
NetBeans 出力ウィンドウ文字化け
NetBeansの出力ウィンドウで日本語が文字化けします。
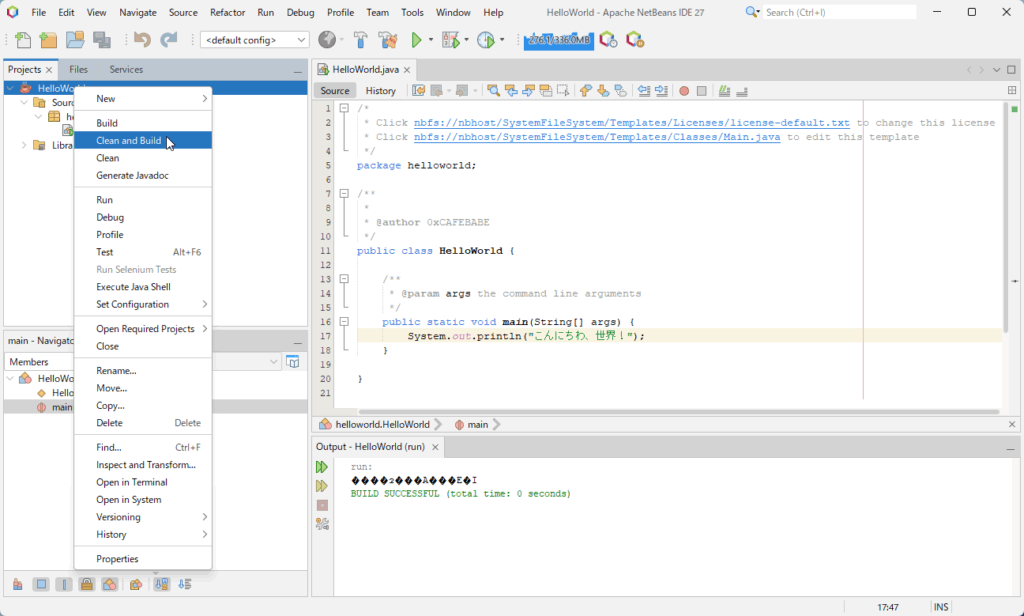
これは、Java 18からエンコーディング関係に変更があったからのようです。
Java 17では文字化けしません。
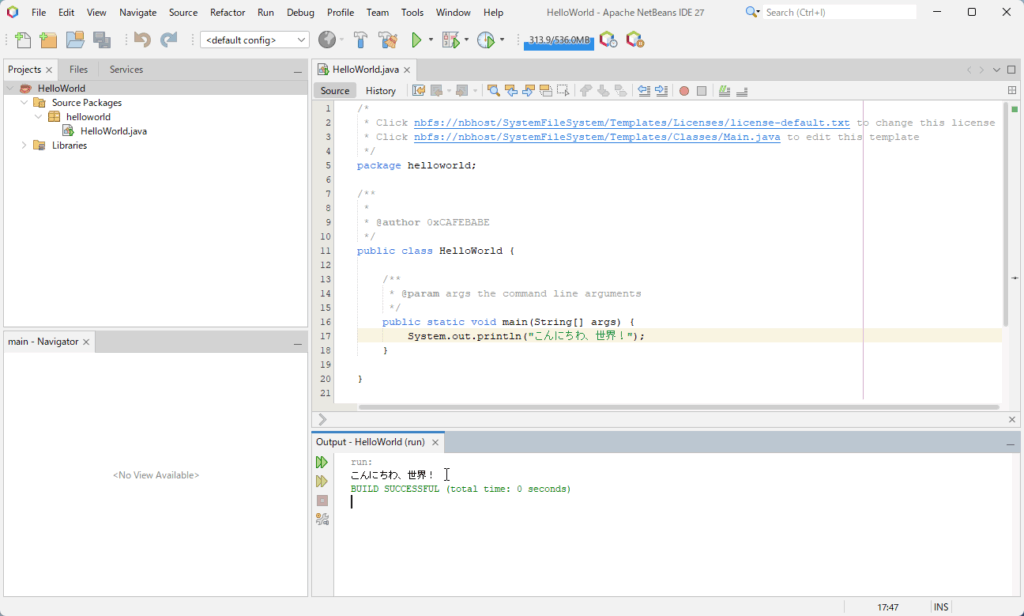
少しコードを付け加えてJDK 24とJDK 17の違いを動作検証します。
Java 24とJava 17での動作検証
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
package helloworld; import java.io.Console; import java.nio.charset.Charset; /** * * @author 0xCAFEBABE */ public class HelloWorld { /** * @param args the command line arguments */ public static void main(String[] args) { System.out.println("Java Runtime version: " + System.getProperty("java.runtime.version")); System.out.println("file.encoding: " + System.getProperty("file.encoding")); System.out.println("native.encoding: " + System.getProperty("native.encoding")); System.out.println("sun.jnu.encoding: " + System.getProperty("sun.jnu.encoding")); System.out.println("sun.stdout.encoding: " + System.getProperty("sun.stdout.encoding")); System.out.println("sun.stderr.encoding: " + System.getProperty("sun.stderr.encoding")); System.out.println("stdout.encoding: " + System.getProperty("stdout.encoding")); System.out.println("stderr.encoding: " + System.getProperty("stderr.encoding")); Console console = System.console(); if (console != null) { Charset charset = console.charset(); System.out.println("Console charset: " + charset); } else { System.out.println("Console is not available."); } System.out.println("Default charset: " + Charset.defaultCharset()); System.out.println("こんにちわ、世界!"); } } |
このプログラムをざっくりと説明します。
16行目は、Java Runtime versionを表示させます。
17行目は、file.encodingを表示させます。
file.encodingとは、Javaアプリケーションがファイルの読み書きや標準入出力を行う際に使うデフォルトの文字エンコーディングです。
18行目は、native.encodingを表示させます。
native.encodingとは、Java 17以降で導入された新しいプロパティで、Java仮想マシン(JVM)が起動されたホスト環境のネイティブ文字エンコーディングを表します。これは、Javaが内部的に使うエンコーディングの基準点として利用されることがあります。
native.encodingがなぜ導入されたのか?
Java 18でJEP 400: UTF-8 by Defaultが導入され、file.encodingのデフォルトがUTF-8に統一されました。
これにより、従来のようにOS依存のエンコーディングが使われなくなったため、元のネイティブエンコーディングを保持するためのプロパティとしてnative.encoding が追加されました。
JEP 400: UTF-8 by Defaultの準備としてJava 17で導入されたようです。
19行目のsun.jnu.encodingとは、ファイル名やパス名など、OSとのやり取りに使われる文字エンコーディングを示す非公開のシステムプロパティです。
これは、Javaアプリケーションがネイティブ環境と文字列をやり取りする際のエンコード方式を定義しています。
主に Windows環境で重要になります。たとえば、Windowsではfile.encodingがUTF-8でも、sun.jnu.encodingはMS932になることがあります。
Javaがファイル名やディレクトリ名を扱うとき、OSのロケールに基づいてこのエンコーディングが使われます。
20行目のsun.stdout.encodingとは、Java仮想マシンが標準出力に使う文字エンコーディングです。
これは、Javaがコンソールやターミナルに文字列を出力する際に、どの文字コードでエンコードするかを決定するために使われます。
21行目のsun.stderr.encodingとは、Java仮想マシンが標準エラー出力に使う文字エンコーディングです。
エラーを出力する際に、どの文字コードでコンソールに表示するかを決定するために使われます。
22行目のstdout.encodingは、Java 19から導入されました。
非公式プロパティだったsun.stdout.encodingを公式プロパティとしてリネームされたようです。
23行目のstderr.encodingは、Java 19から導入されました。
非公式プロパティだったsun.stderr.encodingを公式プロパティとしてリネームされたようです。
24行目から30行目は、コンソールが使用する文字セットを取得します。
これは、標準出力や入力がどの文字コードで動作しているかを確認することができます。
31行目は、Charset.defaultCharset()がデフォルトの文字セットを返します。
デフォルトの文字セットは仮想マシンの起動時に決定されますが、それは通常、オペレーティング・システムのロケールと文字セットによって決まります。
では、Java 24とJava 17をJDK(Java Development Kit)を切り替えプログラムの実行させます。
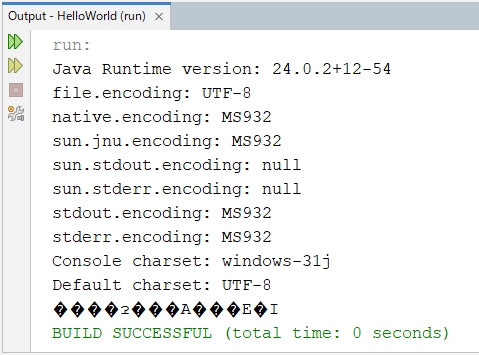
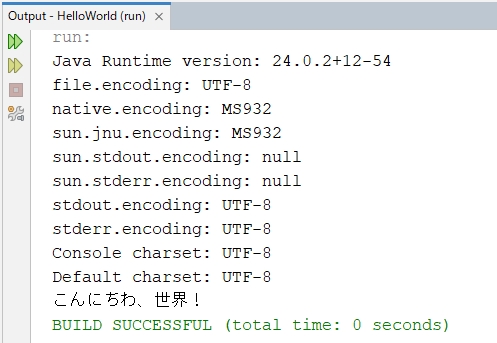
このような実行結果となりました。
Java 24
Java 17
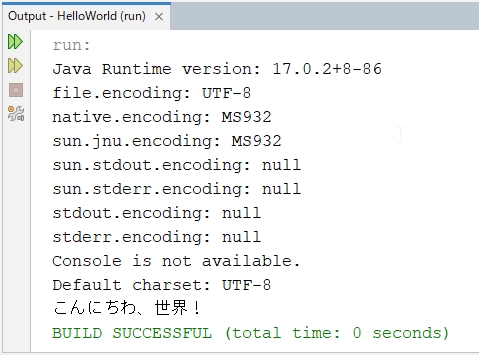
Java 24は、stdout.encodingとstderr.encodingがMS932に設定されています。
Java 17は、stdout.encoding、stderr.encoding、sun.stdout.encoding、sun.stderr.encodingがnullとなっています。
NetBeansの出力ウィンドウは、UTF-8なので文字化けするのは当然の結果です。
何故このようなことになっているか少し調べてみました。
Java 24では標準出力の文字コードはどのように決定される?
Java 24では、stdout.encodingを指定することで、標準出力の文字コードを明示的に設定できます。
例:java -Dstdout.encoding=UTF-8 -jar HelloWorld.jar
stderr.encodingも同様に設定できます。
例:java -Dstdout.encoding=UTF-8 -Dstderr.encoding=UTF-8 -jar HelloWorld.jar
stdout.encoding、stderr.encodingが設定されていない場合、JVM(Java Virtual Machine)は、
sun.stdout.encoding、sun.stderr.encodingを参照することがあります。
上記が設定されていない場合、JVMはOSのロケールやコンソールのコードページ
WindowsならGetConsoleOutputCP()を元に、native.encodingを決定し、それをstdout.encoding、stderr.encodingに使うことがあります。
JEP 400: UTF-8 by Defaultにより、デフォルトの文字セットがUTF-8に変更されましたが、これは標準出力には適用されません。
つまり、 標準出力の文字コードは環境依存のようです。
Java 17では標準出力の文字コードはどのように決定される?
OSのロケール・環境変数を取得して決定。
しかし、file.encodingのプロパティの文字セットを使用します。
上記プログラムではUTF-8です。
Charset.defaultCharset()メソッドでUTF-8が確認できます。
NetBeansの出力ウィンドウ(コンソール出力)はUTF-8なので文字化けせずに正常に出力ウィンドウに日本語が表示されます。
NetBeansでのJava 17では、native.encodingがsun.stdout.encoding、sun.stderr.encodingに使われていません。
Windowsのコマンドプロンプトで実行するとこうなります。
file.encodingがMS932、native.encodingがMS932、sun.jnu.encodingがMS932、そしてsun.stdout.encodingとsun.stderr.encodingがms932となっています。(何故かMSが小文字になっていてms932です。)
WindowsのコマンドプロンプトはMS932なのでsun.stdout.encodingとsun.stderr.encodingがms932となっているので正常に出力されています。
Console charsetとDefault charsetがwindows-31jとなっています。これはMS932と同じです。
NetBeansではConsole charsetが取得できなかったけどコマンドプロンプトで実行すると取得できました。
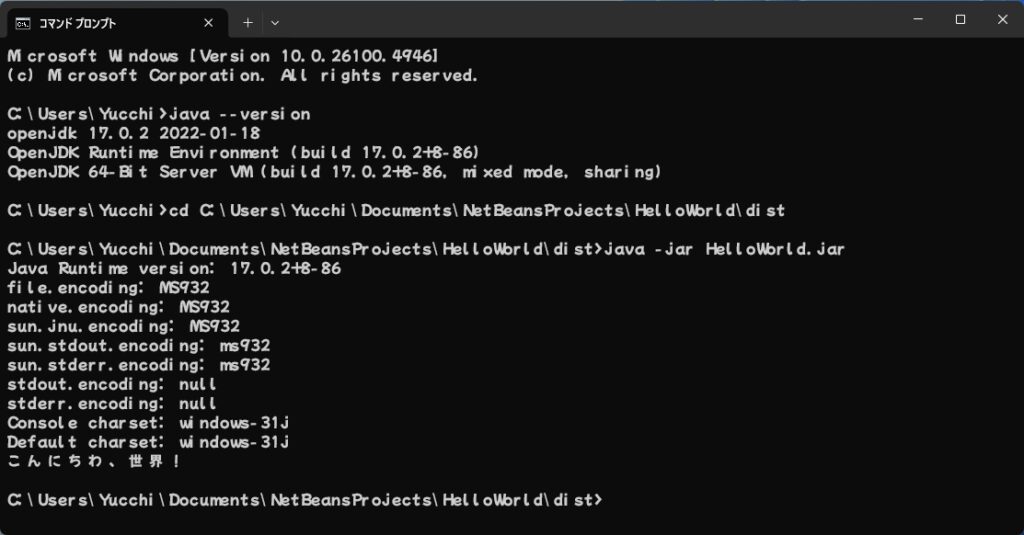
Java 24は、Windowsのコマンドプロンプトではstdout.encoding、stderr.encodingがms932が設定されているので文字化けせずに表示されています。
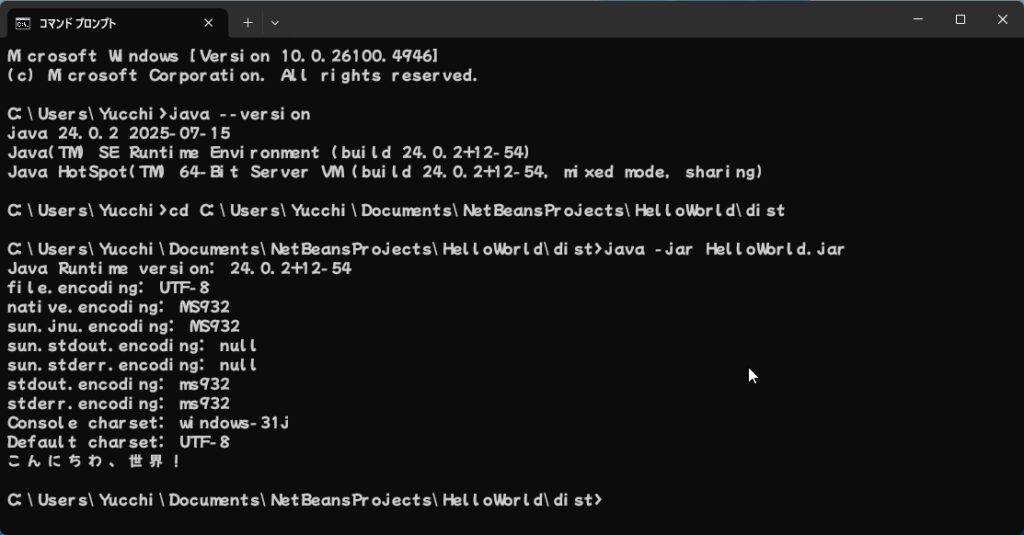
以上の動作検証からNetBeansは、JEP 400: UTF-8 by Defaultの影響?を受けてまだ対応できてないような気がします。
JEP 400: UTF-8 by Default
JEP 400: UTF-8 by Defaultについて少し調べてみます。
OpenJDKのJEP 400: UTF-8 by Defaultより
要約
これは、標準Java APIのデフォルト文字コードをUTF-8に指定し、この変更により、デフォルト文字コードに依存するAPIは、すべての実装、オペレーティングシステム、ロケール、構成において一貫した動作をすることがねらいのようです。
目標
目標として次の3項目が挙げられています。
1.Javaプログラムのコードがデフォルトの文字セットに依存する場合、その予測可能性と移植性を向上させる。
2.標準Java APIがデフォルトの文字セットを使用する箇所を明確化する。
3.コンソール入出力を除き、標準Java API全体でUTF-8を標準化する。
動機
デフォルトの文字セットは環境によって異なるため、デフォルト文字セットを使用するAPIは、経験豊富な開発者であっても多くの予期せぬ危険を伴います。
確かに文字化けは以前から多くのプログラマを悩ませてきました。
java.io.FileReader(“hello.txt”) -> “こんにちは” (macOS)
java.io.FileReader(“hello.txt”) -> “ã?“ã‚“ã?«ã?¡ã? ” (Windows (en-US))
java.io.FileReader(“hello.txt”) -> “縺ォ縺。縺ッ” (Windows (ja-JP)
このような危険性を認識しているプログラマは、明示的に文字セット引数を取るメソッドやコンストラクタを利用できます。
ただし、引数の渡しが必須となるため、ストリームパイプライン内でメソッド参照を介してこれらのメソッドやコンストラクタを使用することはできません。
プログラマはコマンドラインでシステムプロパティ file.encoding を設定してデフォルトの文字セットを構成しようとすることがありますが(例: java -Dfile.encoding=…)、これはサポートされていません。さらに、Java ランタイム起動後にプログラムでプロパティを設定しようとすると(例: System.setProperty(…))、機能しません。
標準的なJava APIのすべてがJDKのデフォルト文字コード選択に従うわけではありません。
例えば、java.nio.file.FilesのメソッドでCharset引数なしでファイルを読み書きする場合、常にUTF-8を使用すると規定されています。
新しいAPIがUTF-8をデフォルトとする一方で、古いAPIがデフォルト文字コードを使用する仕様は、複数のAPIを混在して使用するアプリケーションにとって危険要因となります。
デフォルトの文字セットがどこでも同じに指定されれば、Javaエコシステム全体が恩恵を受けるでしょう。
移植性を考慮しないアプリケーションにはほとんど影響がなく、文字セット引数を渡すことで移植性を実現するアプリケーションには全く影響がありません。
UTF-8は長らくWorld Wide Webで最も一般的な文字セットです。
膨大な数のJavaプログラムが処理するXMLやJSONファイルの標準であり、Java自身のAPIでもNIO APIやプロパティファイルなどにおいてUTF-8がますます推奨されています。
したがって、すべてのJava APIのデフォルト文字セットとしてUTF-8を指定することは合理的です。
この変更がJDK 18に移行するプログラムに広範な互換性影響を与える可能性があることを認識しています。
このため、デフォルト文字セットが環境依存となるJDK 18以前の動作を常に復元できるようにします。
説明
JDK 17およびそれ以前のバージョンでは、デフォルトの文字セットはJavaランタイムの起動時に決定されます。
macOSでは、POSIX Cロケールを除きUTF-8となります。
その他のオペレーティングシステムでは、ユーザーのロケールとデフォルトのエンコーディングに依存します。
例えば、Windowsでは、windows-1252やwindows-31jなどのコードページベースの文字セットになります。
メソッド java.nio.charsets.Charset.defaultCharset() はデフォルトの文字セットを返します。
現在のJDKのデフォルト文字セットを簡単に確認する方法は、次のコマンドを使用することです:
java -XshowSettings:properties -version 2>&1 | grep file.encoding
いくつかの標準Java APIはデフォルトの文字セットを使用します。これには以下が含まれます:
java.ioパッケージでは、InputStreamReader、FileReader、OutputStreamWriter、FileWriter、PrintStreamが、デフォルトの文字セットを使用してエンコードまたはデコードするリーダー、ライター、およびプリントストリームを作成するコンストラクタを定義しています。
java.utilパッケージでは、FormatterとScannerがデフォルト文字セットを使用する結果を生成するコンストラクタを定義しています。
java.netパッケージでは、URLEncoderとURLDecoderがデフォルト文字セットを使用する非推奨メソッドを定義しています。
Charset.defaultCharset() の仕様を変更し、実装固有の方法で別段の設定がなされない限り、デフォルトの文字セットは UTF-8 であると規定することを提案します。(JDKの設定方法については後述)
UTF-8文字セットはRFC 2279で規定されており、その基盤となる変換形式はISO 10646-1の修正2で規定され、Unicode標準でも説明されています。修正UTF-8と混同しないでください。
デフォルト文字セットを使用するすべての標準Java APIの仕様を更新し、Charset.defaultCharset()への相互参照を追加します。
対象APIには上記で挙げたものが含まれますが、System.outおよびSystem.errは除きます。
これらの文字セットはConsole.charset()で指定されるものとなります。
The file.encoding and native.encoding system properties
Charset.defaultCharset() の仕様で想定されているように、JDK はデフォルトの文字セットを UTF-8 以外のものに設定できるようにします。
システムプロパティ file.encoding の扱いを改訂し、コマンドラインでの設定をデフォルト文字セットの設定としてサポートする手段とします。
これを System.getProperties() の実装注記に以下のように明記します:
file.encoding が 「COMPAT」 に設定されている場合(例: java -Dfile.encoding=COMPAT)、デフォルトの文字セットは JDK 17 以前でアルゴリズムによって選択される文字セットとなります。この選択はユーザーのオペレーティングシステム、ロケール、その他の要因に基づきます。file.encoding の値は、その文字セットの名前に設定されます。
file.encoding が 「UTF-8」 に設定されている場合(例: java -Dfile.encoding=UTF-8)、デフォルトの文字セットは UTF-8 になります。
このノーオペレーション値は、既存のコマンドラインの動作を維持するために定義されています。
「COMPAT」および「UTF-8」以外の値の扱いは規定されていません。
これらはサポートされていませんが、JDK 17 で動作した場合は JDK 18 でも動作し続ける可能性が高いです。
file.encoding が 「COMPAT」 に設定されている場合(例: java -Dfile.encoding=COMPAT)、デフォルトの文字セットは JDK 17 以前でアルゴリズムによって選択される文字セットとなります。
この選択はユーザーのオペレーティングシステム、ロケール、その他の要因に基づきます。file.encoding の値は、その文字セットの名前に設定されます。
file.encoding が 「UTF-8」 に設定されている場合(例: java -Dfile.encoding=UTF-8)、デフォルトの文字セットは UTF-8 になります。
このノーオペレーション値は、既存のコマンドラインの動作を維持するために定義されています。
「COMPAT」および「UTF-8」以外の値の扱いは規定されていません。これらはサポートされていませんが、JDK 17 で動作した場合は JDK 18 でも動作し続ける可能性が高いです。
UTF-8がデフォルトの文字コードであるJDKにデプロイする前に、開発者は現在のJDK(8~17)でjava -Dfile.encoding=UTF-8 … を指定してJavaランタイムを起動し、文字コードの問題を確認することを強く推奨します。
JDK 17では、プログラムがJDKのアルゴリズムによって選択された文字セットを取得するための標準的な方法として、native.encodingシステムプロパティが導入されました。
これは、デフォルトの文字セットが実際にその文字セットに設定されているかどうかに関係なく機能します。
JDK 18 では、コマンドラインで file.encoding が COMPAT に設定されている場合、file.encoding の実行時値は native.encoding の実行時値と同じになります。
一方、コマンドラインで file.encoding が UTF-8 に設定されている場合、file.encoding の実行時値は native.encoding の実行時値と異なる可能性があります。
以下の「リスクと前提条件」では、file.encodingの変更、およびnative.encodingシステムプロパティから生じる可能性のある非互換性を緩和する方法と、アプリケーション向けの推奨事項について説明します。
JDK内部で使用される文字セット関連のシステムプロパティは3つあります。
これらは未指定かつ非サポートのままですが、完全性を期すためここに文書化します:
sun.stdout.encoding および sun.stderr.encoding — 標準出力ストリーム (System.out) および標準エラーストリーム (System.err)、ならびに java.io.Console API で使用される文字セットの名前。
sun.jnu.encoding — java.nio.file の実装がファイル名パスのエンコード/デコードに使用する文字セットの名前(ファイル内容とは対照的)。
macOS では値は 「UTF-8」、その他のプラットフォームでは通常デフォルトの文字セット。
Source file encoding
Java言語では、ソースコードがUTF-16エンコーディングでUnicode文字を表現することが可能であり、これはデフォルトの文字セットとしてUTF-8が選択されても影響を受けません。
ただし、javacコンパイラは影響を受けます。なぜなら、-encodingオプションで別段の設定がなされない限り、.javaソースファイルはデフォルトの文字セットでエンコードされていると仮定するからです。
非UTF-8エンコーディングで保存されたソースファイルを旧JDKでコンパイルした場合、JDK 18以降で再コンパイルすると問題が発生する可能性があります。
例えば、非UTF-8ソースファイルに非ASCII文字を含む文字列リテラルがある場合、-encodingオプションを使用しない限り、JDK 18以降のjavacによってそれらのリテラルが誤って解釈される可能性があります。
UTF-8がデフォルトの文字コードであるJDKでコンパイルする前に、開発者は現在のJDK(8-17)でjavac -encoding UTF-8 … を用いてコンパイルし、文字コードの問題を確認することを強く推奨します。
あるいは、非UTF-8エンコーディングでソースファイルを保存することを好む開発者は、JDK 17以降において-encodingオプションをnative.encodingシステムプロパティの値に設定することで、javacがUTF-8を仮定するのを防ぐことができます。
従来のデフォルト文字コード
JDK 17 以前では、名前「default」は US-ASCII 文字セットの別名として認識されます。
つまり、Charset.forName(「default」) は Charset.forName(「US-ASCII」) と同じ結果を生成します。
このデフォルトエイリアスは、sun.io コンバータを使用していたレガシーコードが、JDK 1.4 で導入された java.nio.charset フレームワークへ移行できるようにするため、JDK 1.5 で導入されました。
JDK 18において、デフォルト文字セットがUTF-8と指定されている状況で、defaultをUS-ASCIIの別名として維持することは極めて混乱を招くでしょう。
また、ユーザーがコマンドラインで-Dfile.encoding=COMPATを設定し、デフォルト文字セットをJDK 18以前の値に設定した場合に、defaultがUS-ASCIIを意味することも同様に混乱を招きます。
デフォルトをUS-ASCIIではなく、デフォルトの文字セット(UTF-8かユーザー設定かに関わらず)の別名として再定義すると、Charset.forName(「default」)を呼び出す(ごく一部の)プログラムで微妙な動作変更が生じます。
JDK 18においてデフォルトを継続的に認識することは、不適切な決定を長引かせることになると考えます。
これはJava SEプラットフォームによって定義されておらず、IANAによってもいかなる文字セットの名称または別名として認識されていません。
実際、ASCIIベースのネットワークプロトコルでは、IANAは単なるASCIIやANSI_X3.4-1968のような不明瞭な別名ではなく、正規名US-ASCIIの使用を推奨しています。
つまり、JDK固有の別名defaultの使用は、この勧告に明らかに反するものです。
Javaプログラムでは、Charset.forName(…)に文字列を渡す代わりに、enum定数StandardCharsets.US_ASCIIを使用することで意図を明確にできる。したがって、JDK 18 では Charset.forName(「default」) は UnsupportedCharsetException をスローします。
これにより開発者はこのイディオムの使用を検知し、US-ASCII または Charset.defaultCharset() の結果への移行が可能になります。
テスト
この変更による互換性への影響範囲を把握するには、十分なテストが必要です。地理的に分散したユーザー基盤を持つ開発者や組織によるテストが求められます。
開発者は、この変更を含む早期アクセス版や一般提供版リリースに先立ち、-Dfile.encoding=UTF-8 オプションを指定して実行することで、既存のJDKリリースにおける問題を確認できます。
リスクと前提条件
多くの環境におけるアプリケーションは、JavaがUTF-8を選択したことによる影響を受けないと想定しています:
macOSでは、POSIX Cロケールを使用するように設定されている場合を除き、数世代前からデフォルトの文字コードはUTF-8となっています。
多くのLinuxディストリビューション(すべてではありませんが)ではデフォルトの文字コードがUTF-8であるため、これらの環境では変更は認識されません。
多くのサーバーアプリケーションは既に-Dfile.encoding=UTF-8で起動されているため、変更の影響を受けません。
他の環境では、20年以上経った後にデフォルトの文字セットをUTF-8に変更するリスクは重大である可能性があります。
最も明らかなリスクは、デフォルトの文字セットに暗黙的に依存しているアプリケーション(例:APIに明示的な文字セット引数を渡さない場合)が、デフォルトの文字セットが指定されていない状態で生成されたデータを処理する際に不正な動作をする可能性があることです。
さらに、データ破損が黙って発生するリスクもあります。
主な影響は、アジア地域のロケールでWindowsを利用するユーザー、およびアジアその他の地域のサーバー環境の一部で生じると予想されます。
想定されるシナリオには以下が含まれます:
長年デフォルト文字コードとしてwindows-31jで動作してきたアプリケーションを、デフォルト文字コードがUTF-8のJDKリリースにアップグレードした場合、windows-31jでエンコードされたファイルを読み込む際に問題が発生します。
この場合、該当ファイルを開く際にwindows-31j文字コードを渡すようアプリケーションコードを変更できます。
コードを変更できない場合、Javaランタイムを-Dfile.encoding=COMPATオプションで起動すると、アプリケーションの更新またはファイルのUTF-8変換が行われるまで、デフォルト文字コードがWindows-31Jに強制されます。
複数のJDKバージョンが使用されている環境では、ユーザー間でファイルデータの交換ができない場合があります。
例えば、あるユーザーがwindows-31jをデフォルトとする古いJDKリリースを使用し、別のユーザーがUTF-8をデフォルトとする新しいJDKを使用している場合、前者のユーザーが作成したテキストファイルは後者のユーザーでは読み込めない可能性があります。
この場合、古いJDKリリースを使用するユーザーはアプリケーション起動時に-Dfile.encoding=UTF-8を指定するか、新しいリリースを使用するユーザーは-Dfile.encoding=COMPATを指定できます。
アプリケーションコードを変更できる場合は、コンストラクタに文字コード引数を渡すように変更することを推奨します。
アプリケーションが特定の文字コードを指定せず、デフォルト文字コードを従来の環境設定による選択で問題ない場合、以下のコードを使用すればすべてのJavaリリースにおいて環境から決定された文字コードを取得できます:
String encoding = System.getProperty(“native.encoding”); // Populated on Java 18 and later
Charset cs = (encoding != null) ? Charset.forName(encoding) : Charset.defaultCharset();
var reader = new FileReader(“file.txt”, cs);
アプリケーションコードもJavaの起動処理も変更できない場合、JDK 18上で互換性を持って動作するかどうかを判断するために、アプリケーションコードを手動で検査する必要があります。
代替案
現状維持 — これにより上記の危険性は解消されません。
Java API においてデフォルト文字セットを使用する全てのメソッドを非推奨とする — これにより開発者は文字セットパラメータを取るコンストラクタやメソッドの使用を促されますが、結果としてコードは冗長になります。
変更手段を提供せずにUTF-8をデフォルト文字セットとして指定する — この変更による互換性への影響が大きすぎます。
NetBeans 文字化け対策
OpenJDKのJEP 400: UTF-8 by Defaultにもあるように、コンソール入出力を除き、標準Java API全体でUTF-8を標準化すると明記されているので、Javaの動作的には問題がないようです。
この問題は、NetBeansの出力ウィンドウがUTF-8だからそれに対処するしかなさそうです。
VM Optionsを設定
JVM (Java Virtual Machine) に標準出力の文字コードを明示的に設定します。
NetBeansのプロジェクトHelloWorldを右クリックしてポップアップメニューからPropertiesをクリックしてプロパティウインドウを出します。
カテゴリーからRunを選択して、VM Options:に-Dstdout.encoding=UTF-8 -Dstderr.encoding=UTF-8を設定します。
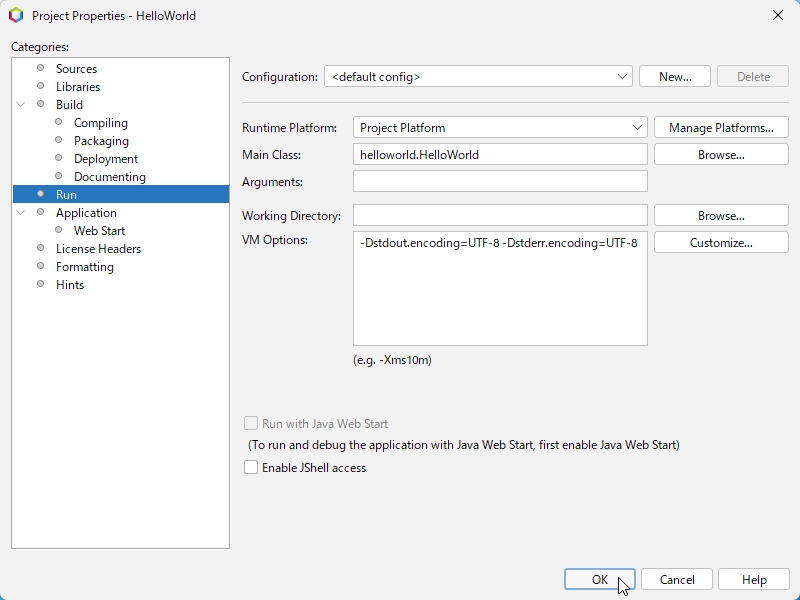
これでUTF-8で出力されます。
文字化けせずに正常に出力されました。
JAVA_TOOL_OPTIONS環境変数を設定したバッチファイルを作る
プロジェクト作成するたびに上記のようにVMオプションを設定するのも面倒なのでJAVA_TOOL_OPTIONS環境変数を設定したNetBeans起動用のバッチファイルを作成します。
JAVA_TOOL_OPTIONS環境変数とは、Java Virtual Machineにオプションを渡せる環境変数です。
テキストエディタを開いて下記のように記述します。
set JAVA_TOOL_OPTIONS=-Dstdout.encoding=UTF-8 -Dstderr.encoding=UTF-8
start “” “C:\Apache NetBeans 27\netbeans-27-bin\netbeans\bin\netbeans64.exe”
これを適当な名前でデスクトップに保存すれば便利です。
このバッチファイルからNetBeansを立ち上げた場合だけこのJAVA_TOOL_OPTIONS環境変数が適用されます。
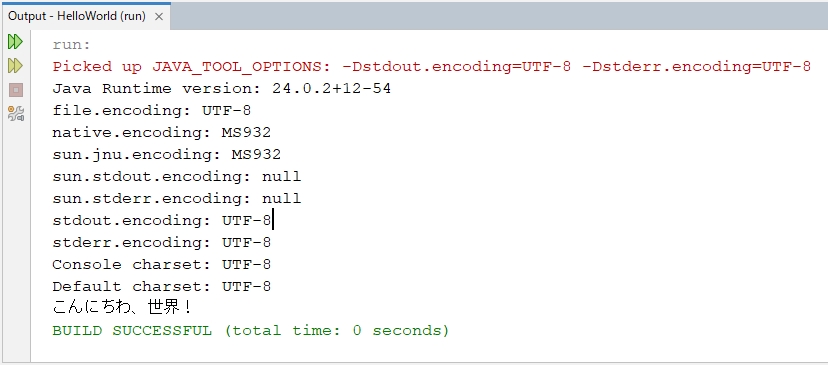
これで、NetBeansの出力ウィンドウの文字化けは解決です。
できることならNetBeans側で出力ウィンドウの文字セットを変更するオプションがあるといいな・・・



コメント